Here is a poll about what are the concerns for people about privacy.
Category Archives: privacy
Proportionality Design Method
Leave a reply
The principle of Data Quality from the Fair Information Practices insinuates that the information that is obtained from the users should be applied to their benefit:
| “Personal data should be relevant to the purposes for which they are to be used, and, to the extent necessary for those purposes, should be accurate, complete and kept up-to-date.” |
Giovanni Iachello and Gregory D. Abowd use this as a starting point and elaborate the principle of proportionality:
| “Any application, system, tool or process should balance its utility with the rights to privacy (personal, informational, etc.) of the involved individuals” |
Based on this principle, they propose the Proportionality design method:
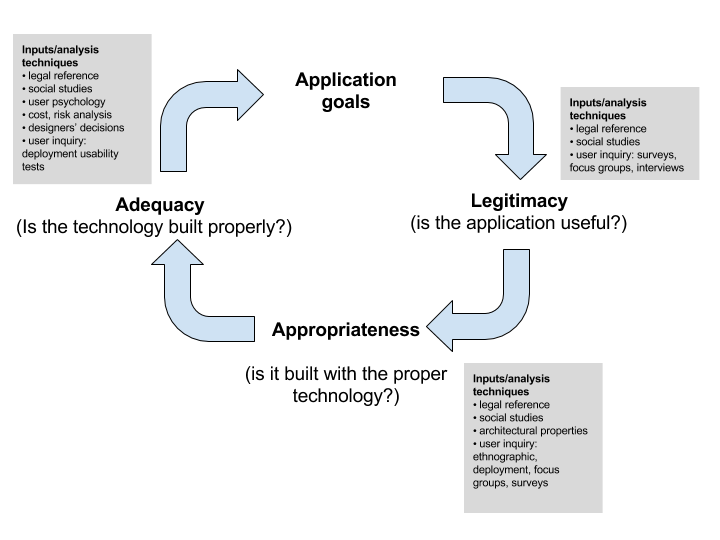
Proportionality Design Method
During the whole development cycle of the application, the different parts need to verify the legitimacy, appropriateness and adequacy of the application:
- Legitimacy: Verify that the application is useful to the user. What is the function that the application cover?
- Appropriateness:Analyse if the alternative implementations with the different technologies satisfy the goal of the application without supposing a risk for the privacy of the users?
- Adequacy: Analyse if the different alternative technologies are correctly implemented.
Sources:
G. Iachello and G. D. Abowd, “Privacy and proportionality: adapting legal evaluation techniques to inform design in ubiquitous computing,” in Proceedings of the SIGCHI conference on Human factors in computing systems, 2005, pp. 91–100.Privacy Risk Models
Jason Hong, Jennifer D. Ng, Scott Lederer and James A. Landay present their framework for modelling privacy risks in ubiquitous computing environments.
The privacy risk models framework consists of two parts: privacy risk analysis, that proposes a list of questions to help defining the context of use of the future application and the privacy risk management, which is a cost-benefit analysis that is used to prioritise the privacy risks and develop the system.
Privacy risk analysis
The privacy risk analysis starts with the formulation of the following questions grouped in the categories Social and Organisational Context and Technology:
Social and Organizational Context
Technology
|
Privacy Risk Management
This part consists on the prioritisation of privacy risks applying the inequality known as the Hand’s rule.
|
C < L×D Being:
|
References
J. I. Hong, J. D. Ng, S. Lederer, and J. A. Landay, “Privacy risk models for designing privacy-sensitive ubiquitous computing systems,” in Proceedings of the 5th conference on Designing interactive systems: processes, practices, methods, and techniques, 2004, pp. 91–100.